老徐小屋
老徐小屋搬瓦工的机器ssh连接不上
直接使用重装
yum install -y openssh-server
搬瓦工的机器ssh连接不上
直接使用重装
yum install -y openssh-server
首先 Zerotier 是什么呢? Zerotier 是一拨人为了解决网络复杂,以及因特网过于中心化而提出的解决方案。他们使用点对点 的网络,并且在上面附加一层 VXLAN-like 虚拟网络层 来提高局域网的可见性,安全性。
所以简单来说,Zerotier 通过创建一个虚拟网络,把你的设备添加到这个网络,那么在这个网络内,你的设备就像在同一个路由器内那样可以使用各种端口。
免费版 Zerotier 支持局域网内 100 个设备。Zerotier 支持 Windows、macOS、Linux 三大桌面平台,iOS、Android 两大移动平台,QNAP(威连通)、Synology(群晖)、Western Digital MyCloud NAS(西部数据)三个 NAS 平台,还支持 OpenWrt/LEDE 开源路由器项目。
官网地址:
zerotier-cli join <network id>(或在网页上添加 ZeroTier address)Windows 系统用命令 IPconfig,Linux/Unix 用命令 ifconfig,然后会看到一个虚拟网卡,有一个 IP 地址。这个 IP 和在官网看到的 network 下的 IP 是一致的,只有同在该虚拟网络下的机器才能访问。
接下来,你可以设置远程桌面(端口号 3389),或者 FTP 服务(端口 21),或者搭建内网网站(端口 80),各种玩法都可以尝试咯。
图文教程可以参考这篇文章
和 ngrok 和 frp 功能类似,但是 ZeroTier 明显入手简单。ZeroTier 只有客户端开源,服务端并没有开源。而 ngrok 和 frp 都是完全开源。但是 ngrok 和 frp 严重依赖于公网固定 IP 的 VPS,是一个中性化的内网穿透工具,一旦中心挂掉,那么所有的节点都无法工作。Zerotier 帮助用户实现了服务端,虽然安全性有待考验,但至少还是能用状态。
另外很多人提到的 N2N 开上去也不错,不过我还没怎么用过。等以后尝试过后再补上。
Centos7客户端安装
1、编辑添加yum源
|
1 |
vi /etc/yum.repos.d/zerotier.repo |
修改内容如下
|
1 2 3 4 5 |
[zerotier] name=ZeroTier, Inc. RPM Release Repository baseurl=http://download.zerotier.com/redhat/el/$releasever enabled=1 gpgcheck=0 |
2、安装zerotier
|
1 2 |
yum clean all yum install zerotier-one |
3、启动服务
|
1 |
zerotier-one -d |
4、查看服务状态
|
1 |
zerotier-cli status |
看到200 info 596811110b 1.2.12 ONLINE表示服务正常
可以使用netstat命令看到所启动的服务端口(这里192.168.1.162是centos本机的IP)
5、加入网络(后面是你自己的ID号)
|
1 |
zerotier-cli join Network ID a0cbf4b62ad6066c 这个ID是你账号的ID |
加入后会提示200 join OK
进入https://my.zerotier.com/network
刷新几次页面即可看到新加入的主机,然后在前面勾选即可,勾选后Version会变成版本号,并且会分配出一个IP地址
6、主机验证
回到centos7主机上通过ifconfig命令即可看到,此处又多了一个内网IP,此内网IP和zerotier一致,表示配置完成
附:加入、离开、列出网络状态
|
1 2 3 |
zerotier-cli join Network ID zerotier-cli leave Network ID zerotier-cli listnetworks |
Zerotier 的官方服务器在国外,国内客户端使用时延迟较大,网络高峰期时甚至各个客户端节点之间访问不了。此时,“自定义根服务器”,又称 moon 中转服务器就显得非常重要,它的主要功能是通过自定义的服务器作为跳板加速内网机器之间的互相访问。
Zerotier 定义了几个专业名词:
PLANET 行星服务器,Zerotier 各地的根服务器,有日本、新加坡等地moon 卫星级服务器,用户自建的私有根服务器,起到中转加速的作用LEAF 相当于各个枝叶,就是每台连接到该网络的机器节点。在使用 zerotier-cli listpeers 命令时能看到这几个名词。充当 moon 的机子最好有公网 IP,现在我们尝试用 qnap 搭建一个 moon 中转:
虽然搭建了 MOON 服务器,我们还是需要借助 zerotier network,也就是需要先通过 zerotier 官网创建一个 network,并且内网节点需要使用 join 命令加入该网络才能实现内网节点的互通,换句话说 MOON 节点只起到了加速的作用,虚拟网络的分配和管理还是需要 zerotier 服务端参与。
|
1 |
zerotier-cli join <network id> 示例:zerotier-cli join sdf4523424 |
虽然搭建了 MOON 服务器,我们还是需要借助 zerotier network,也就是需要先通过 zerotier 官网创建一个 network,并且内网节点需要使用 join 命令加入该网络才能实现内网节点的互通,换句话说 MOON 节点只起到了加速的作用,虚拟网络的分配和管理还是需要 zerotier 服务端参与
zerotier 安装好之后会带有 zerotier-idtool 这个命令,之后的内容需要依赖该命令。假设现在有一台公网固定 IP 的 VPS,在上面安装完 Zerotier 之后。
|
1 2 |
cd /var/lib/zerotier-one zerotier-idtool initmoon identity.public > moon.json |
获得 moon.json 文件。查看文件内容,其中 id 为 VPS 的 Zerotier ID。 vi 编辑 moon.json,修改 “stableEndpoints” 为 VPS 的公网的 IP,以 IPv4 为例:
|
1 |
"stableEndpoints": [ "8.8.8.8/9993" ] |
8.8.8.8 为公网 IP,9993 为 Zerotier 默认端口。
另外,记录下 json 中的 id 值,是一个 10 位的字符串。
用到上一步中的 moon.json, 执行
|
1 |
zerotier-idtool genmoon moon.json |
执行之后生成 000000xxxx.moon 文件。
在 VPS 的 Zerotier 安装目录下(/var/lib/zerotier-one)建立文件夹 moons.d,将生成的 .moon文件拷贝进去。
重启 zerotier,重启电脑。至此,VPS 上(moon 服务器)配置完成。
重启 zerotier-one
|
1 |
sudo killall -9 zerotier-one |
其他虚拟局域网中的机器想要连接到 moon 节点的话有两种方法,第一种方法就是使用 zerotier-cli orbit 命令。连接 moon 节点方法一,使用之前步骤中 moon.json 文件中的 id 值 (10 位的字符串)
分别在客户端机器里执行:
|
1 |
zerotier-cli orbit <id> <id> 不要<> 示例 zerotier-cli orbit 16acd3d1b4 16acd3d1b4 |
完成
第二种方法是需要在 /var/lib/zerotier-one 目录下新建 moons.d 文件夹和 moon 节点一样,将 000000xxxx.moon 文件放到其中,并重启 zerotier。
|
1 |
zerotier-cli listpeers |
如果有 moon 服务器 IP 地址的那一行后面有 moon 字样,证明 moon 节点已经被本机连接。
不同系统下的 ZeroTier 目录位置:
C:\ProgramData\ZeroTier\One/Library/Application\ Support/ZeroTier/One)/var/lib/zerotier-one/var/db/zerotier-one相信Hyper-v管理员都有这样的经历,安装多台虚拟机后,都要一台一台手工激活,如果虚拟机足够多的话,这是一项很繁琐的工作,但从Windows Server 2012 R2开始,就不需要这么做了,微软提供一项新的技术叫做:Automatic Virtual Machine Activation虚拟机自激活(AVMA)技术。什么?不再需要序列号?不要网络?不用人工?就能激活?没有听错吧?是的,没有听错。只要你的宿主机是Windows Server 2012 R2 Datacenter且宿主机已经激活,不管宿主机许可证是VL,OEM还是零售版,只要宿主主机处于激活状,在其上运行的任何R2 VM都将被激活。当然,一些早期的Server操作系统还得用手动激活,如Windows Server 2008;Windows Server 2008 R2;Windows Server 2012;如果单从技术上来说,让它们自动激活肯定不成问题,从商业和技术的发展来说,大概微软是想让Windows Server 2012 R2更快的推广吧。
虚拟机自激活目前支持的WindowsServer的版本如下:
·Windows Server 2012 R2Datacenter
·Windows Server 2012 R2 Standard
·Windows Server 2012 R2Essentials.
支持WindowsServer 2012 R2虚拟机自激活(AVMA)的Key如下:
Windows Server 2012 R2 Preview Key:
| Edition | AVMA key |
| Datacenter | XVNRV-9HTX4-TH2JD-HVJQD-QRQWG |
| Standard | HXFNP-8HYQ3-4FMC3-2DHJ9-M97JF |
| Essentials | 7VW9N-8C48X-J6442-J3KM6-FVTM9 |
Windows Server 2012 R2 KEY:
| Edition | AVMA key |
| Datacenter | Y4TGP-NPTV9-HTC2H-7MGQ3-DV4TW |
| Standard | DBGBW-NPF86-BJVTX-K3WKJ-MTB6V |
| Essentials | K2XGM-NMBT3-2R6Q8-WF2FK-P36R2 |
那么,如何实现WindowsServer 2012 R2虚拟机自激活(AVMA)技术呢?
1、安装一台WindowsServer 2012 R2 Datacenter的宿主机并添加Hyper-v角色,然后激活它。
2、在Hyper-v中安装一台WindowsServer 2012 R2版的虚拟机。
3、在虚拟机中,打开如下命令:
slmgr /ipk (AVMA key)
(AVMA key)=上表提示的Key。
虚拟机既可自动激活。
是一个兼容 SS/SSR 代理的免费 iOS app。
你可以通过 TestFlight 下载 Potatso Lite
的 Beta 测试版。
TestFlight 是 Apple 官方的软件测试平台。
在 TestFlight 中测试 Potatso Lite。
在网页 (左图) 中点击 “Start Testing”,跳转到 TestFlight 应用中,请选择接受测试并安装 (ACCEPT & INSTALL)。
![[iOS] 没有美区的Apple ID 下载 Potatso Lite 的超简单办法(ShadowRocket的完美替代)](http://www.laoxu.date/wp-content/uploads/2019/07/cfea0-1557230739-5c7e6be24ea92.jpg)
该页面中的链接 / 二维码和密码一样重要,请勿泄漏。如不慎外泄,请立即重置密码。
在 Potatso Lite 添加代理页面中选择 “URI”,将你自己的订阅链接粘贴至输入框中。
![[iOS] 没有美区的Apple ID 下载 Potatso Lite 的超简单办法(ShadowRocket的完美替代)](http://www.laoxu.date/wp-content/uploads/2019/07/1b255-1557230758-5c7e705f797e8.jpeg)
添加后,选择需要使用的节点,滑动上方开关开启即可,建议开启智能路由。
如您首次使用 Potatso Lite, iOS 会要求配置 VPN,需要验证 Touch ID 或设备密码。
操作完成后,你就可以正常访问国际互联网了,之后您可以返回 Potatso Lite 应用切换代理节点或关闭代理,我们建议您 24 小时开启(会有 10% 以下的电量消耗)。
wget 是一个从网络上自动下载文件的自由工具。它支持HTTP,HTTPS和FTP协议,可以使用HTTP代理。
自动下载是指,wget可以在用户退出系统的之后在后台执行。这意味这你可以登录系统,启动一个wget下载任务,然后退出系统,wget将在后台执行直到任务完成,相对于其它大部分浏览器在下载大量数据时需要用户一直的参与,这省去了极大的麻烦。
wget可以跟踪HTML页面上的链接依次下载来创建远程服务器的本地版本,完全重建原始站点的目录结构。这又常被称作”递归下载”。在递归下载的时候,wget 遵循Robot Exclusion标准(/robots.txt). wget可以在下载的同时,将链接转换成指向本地文件,以方便离线浏览。
wget 非常稳定,它在带宽很窄的情况下和不稳定网络中有很强的适应性.如果是由于网络的原因下载失败,wget会不断的尝试,直到整个文件下载完毕。如果是服务 器打断下载过程,它会再次联到服务器上从停止的地方继续下载。这对从那些限定了链接时间的服务器上下载大文件非常有用。
wget的常见用法
wget不但功能强大,而且使用起来比较简单,基本的语法是:wget [参数列表] “URL” 用””引起来可以避免因URL中有特殊字符造成的下载出错。
下面就结合具体的例子来说明一下wget的用法。
1、下载整个http或者ftp站点
wget http://place.your.url/here
这个命令可以将http://place.your.url/here 首页下载下来。使用-x会强制建立服务器上一模一样的目录,如果使用-nd参数,那么服务器上下载的所有内容都会加到本地当前目录。
wget -r http://place.your.url/here
这个命令会按照递归的方法,下载服务器上所有的目录和文件,实质就是下载整个网站。这个命令一定要小心使用,因为在下载的时候,被下载网站指向的所有地址 同样会被下载,因此,如果这个网站引用了其他网站,那么被引用的网站也会被下载下来!基于这个原因,这个参数不常用。可以用-l number参数来指定下载的层次。例如只下载两层,那么使用-l 2。
要是您想制作镜像站点,那么可以使用-m参数,例如:
wget -m http://place.your.url/here
这时wget会自动判断合适的参数来制作镜像站点。此时,wget会登录到服务器上,读入robots.txt并按robots.txt的规定来执行。
2、断点续传
当文件特别大或者网络特别慢的时候,往往一个文件还没有下载完,连接就已经被切断,此时就需要断点续传。wget的断点续传是自动的,只需要使用-c参数,例如:
wget -c http://the.url.of/incomplete/file
使用断点续传要求服务器支持断点续传。-t参数表示重试次数,例如需要重试100次,那么就写-t 100,如果设成-t 0,那么表示无穷次重试,直到连接成功。-T参数表示超时等待时间,例如-T 120,表示等待120秒连接不上就算超时。
3、批量下载
如果有多个文件需要下载,那么可以生成一个文件,把每个文件的URL写一行,例如生成文件download.txt,然后用命令:
wget -i download.txt
这样就会把download.txt里面列出的每个URL都下载下来。(如果列的是文件就下载文件,如果列的是网站,那么下载首页)
4、选择性的下载
可以指定让wget只下载一类文件,或者不下载什么文件。例如:
wget -m –reject=gif http://target.web.site/subdirectory
表示下载http://target.web.site/subdirectory,但是忽略gif文件。–accept=LIST 可以接受的文件类型,–reject=LIST拒绝接受的文件类型。
5、密码和认证
wget只能处理利用用户名/密码方式限制访问的网站,可以利用两个参数:
–http-user=USER 设置HTTP用户
–http-passwd=PASS 设置HTTP密码
对于需要证书做认证的网站,就只能利用其他下载工具了,例如curl。
6、利用代理服务器进行下载
如果用户的网络需要经过代理服务器,那么可以让wget通过代理服务器进行文件的下载。此时需要在当前用户的目录下创建一个.wgetrc文件。文件中可以设置代理服务器:
http-proxy = 111.111.111.111:8080
ftp-proxy = 111.111.111.111:8080
分别表示http的代理服务器和ftp的代理服务器。如果代理服务器需要密码则使用:
–proxy-user=USER 设置代理用户
–proxy-passwd=PASS 设置代理密码
这两个参数,使用参数–proxy=on/off 使用或者关闭代理;wget还有很多有用的功能,需要自己可以去了解一下参数和用法。
wget的使用格式
Usage: wget [OPTION]… [URL]…
1、用wget做站点镜像
wget -r -p -np -k http://dsec.pku.edu.cn/~usr_name/
or
wget -m http://dsec.pku.edu.cn/~usr_name/
2、在不稳定的网络上下载一个部分下载的文件,以及在空闲时段下载
wget -t 0 -w 31 -c http://dsec.pku.edu.cn/BBC.avi -o down.log &
或者从filelist读入要下载的文件列表
wget -t 0 -w 31 -c -B ftp://dsec.pku.edu.cn/linuxsoft -i filelist.txt -o down.log &
上面的代码还可以用来在网络比较空闲的时段进行下载。我的用法是:在mozilla中将不方便当时下载的URL链接拷贝到内存中然后粘贴到文件 filelist.txt中,在晚上要出去系统前执行上面代码的第二条。
3、使用代理下载
wget -Y on -p -k https://sourceforge.net/projects/wvware/
代理可以在环境变量或wgetrc文件中设定。
在环境变量中设定代理:
export PROXY=http://211.90.168.99:8080/
在~/.wgetrc中设定代理:
http_proxy = http://proxy.yoyodyne.com:18023/
ftp_proxy = http://proxy.yoyodyne.com:18023/
wget各种选项分类列表
1、启动
-V, –version 显示wget的版本后退出
-h, –help 打印语法帮助
-b, –background 启动后转入后台执行
-e, –execute=COMMAND 执行.wgetrc’格式的命令,wgetrc格式参见/etc/wgetrc或~/.wgetrcContent-Length’头域
2、记录和输入文件
-o, –output-file=FILE 把记录写到FILE文件中
-a, –append-output=FILE 把记录追加到FILE文件中
-d, –debug 打印调试输出
-q, –quiet 安静模式(没有输出)
-v, –verbose 冗长模式(这是缺省设置)
-nv, –non-verbose 关掉冗长模式,但不是安静模式
-i, –input-file=FILE 下载在FILE文件中出现的URLs
-F, –force-html 把输入文件当作HTML格式文件对待
-B, –base=URL 将URL作为在-F -i参数指定的文件中出现的相对链接的前缀
–sslcertfile=FILE 可选客户端证书
–sslcertkey=KEYFILE 可选客户端证书的KEYFILE
–egd-file=FILE 指定EGD socket的文件名
3、下载
–bind-address=ADDRESS 指定本地使用地址(主机名或IP,当本地有多个IP或名字时使用)
-t, –tries=NUMBER 设定最大尝试链接次数(0 表示无限制).
-O –output-document=FILE 把文档写到FILE文件中
-nc, –no-clobber 不要覆盖存在的文件或使用.#前缀
-c, –continue 接着下载没下载完的文件
–progress=TYPE 设定进程条标记
-N, –timestamping 不要重新下载文件除非比本地文件新
-S, –server-response 打印服务器的回应
–spider 不下载任何东西
-T, –timeout=SECONDS 设定响应超时的秒数
-w, –wait=SECONDS 两次尝试之间间隔SECONDS秒
–waitretry=SECONDS 在重新链接之间等待1…SECONDS秒
–random-wait 在下载之间等待0…2*WAIT秒
-Y, –proxy=on/off 打开或关闭代理
-Q, –quota=NUMBER 设置下载的容量限制
–limit-rate=RATE 限定下载输率
4、目录
-nd –no-directories 不创建目录
-x, –force-directories 强制创建目录
-nH, –no-host-directories 不创建主机目录
-P, –directory-prefix=PREFIX 将文件保存到目录 PREFIX/…
–cut-dirs=NUMBER 忽略 NUMBER层远程目录
5、HTTP选项
–http-user=USER 设定HTTP用户名为 USER.
–http-passwd=PASS 设定http密码为 PASS.
-C, –cache=on/off 允许/不允许服务器端的数据缓存 (一般情况下允许).
-E, –html-extension 将所有text/html文档以.html扩展名保存
–ignore-length 忽略
–header=STRING 在headers中插入字符串 STRING
–proxy-user=USER 设定代理的用户名为 USER
–proxy-passwd=PASS 设定代理的密码为 PASS
–referer=URL 在HTTP请求中包含 Referer: URL’头.listing’文件
-s, –save-headers 保存HTTP头到文件
-U, –user-agent=AGENT 设定代理的名称为 AGENT而不是 Wget/VERSION.
–no-http-keep-alive 关闭 HTTP活动链接 (永远链接).
–cookies=off 不使用 cookies.
–load-cookies=FILE 在开始会话前从文件 FILE中加载cookie
–save-cookies=FILE 在会话结束后将 cookies保存到 FILE文件中
6、FTP选项
-nr, –dont-remove-listing 不移走
-g, –glob=on/off 打开或关闭文件名的 globbing机制
–passive-ftp 使用被动传输模式 (缺省值).
–active-ftp 使用主动传输模式
–retr-symlinks 在递归的时候,将链接指向文件(而不是目录)
7、递归下载
-r, –recursive 递归下载--慎用!
-l, –level=NUMBER 最大递归深度 (inf 或 0 代表无穷).
–delete-after 在现在完毕后局部删除文件
-k, –convert-links 转换非相对链接为相对链接
-K, –backup-converted 在转换文件X之前,将之备份为 X.orig
-m, –mirror 等价于 -r -N -l inf -nr.
-p, –page-requisites 下载显示HTML文件的所有图片
8、递归下载中的包含和不包含(accept/reject)
-A, –accept=LIST 分号分隔的被接受扩展名的列表
-R, –reject=LIST 分号分隔的不被接受的扩展名的列表
-D, –domains=LIST 分号分隔的被接受域的列表
–exclude-domains=LIST 分号分隔的不被接受的域的列表
–follow-ftp 跟踪HTML文档中的FTP链接
–follow-tags=LIST 分号分隔的被跟踪的HTML标签的列表
-G, –ignore-tags=LIST 分号分隔的被忽略的HTML标签的列表
-H, –span-hosts 当递归时转到外部主机
-L, –relative 仅仅跟踪相对链接
-I, –include-directories=LIST 允许目录的列表
-X, –exclude-directories=LIST 不被包含目录的列表
-np, –no-parent 不要追溯到父目录
wget -S –spider url 不下载只显示过程。
———————
作者:菲宇
来源:CSDN
原文:https://blog.csdn.net/bbwangj/article/details/77969970
版权声明:本文为博主原创文章,转载请附上博文链接!
https://zhaoolee.gitbooks.io/chrome/content/
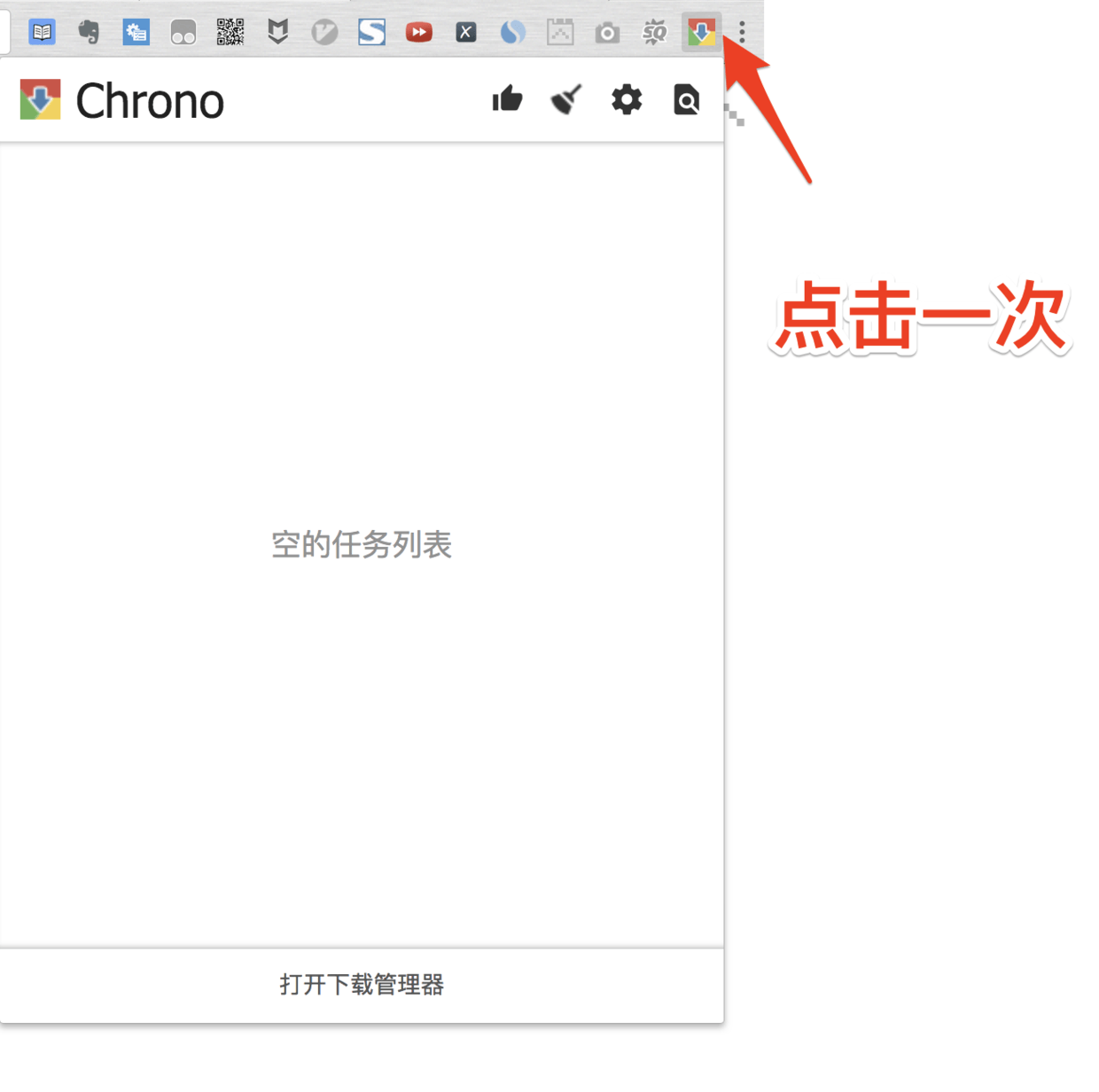
众所周知, chrome原生的下载功能并不好用, 以查看下载任务为例, 我们需要点击两次(点击右上角 三个点 , 点击下载内容) 才能查看当前的任务
而使用了chrono, 只需要点击一次
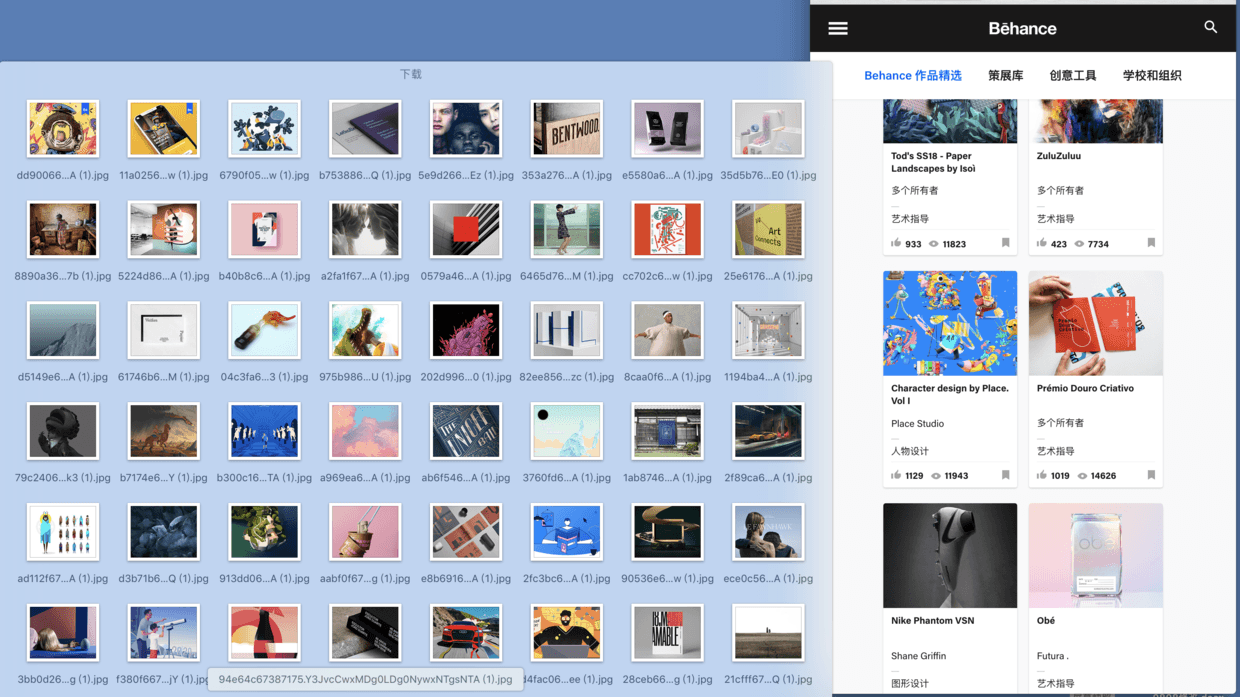
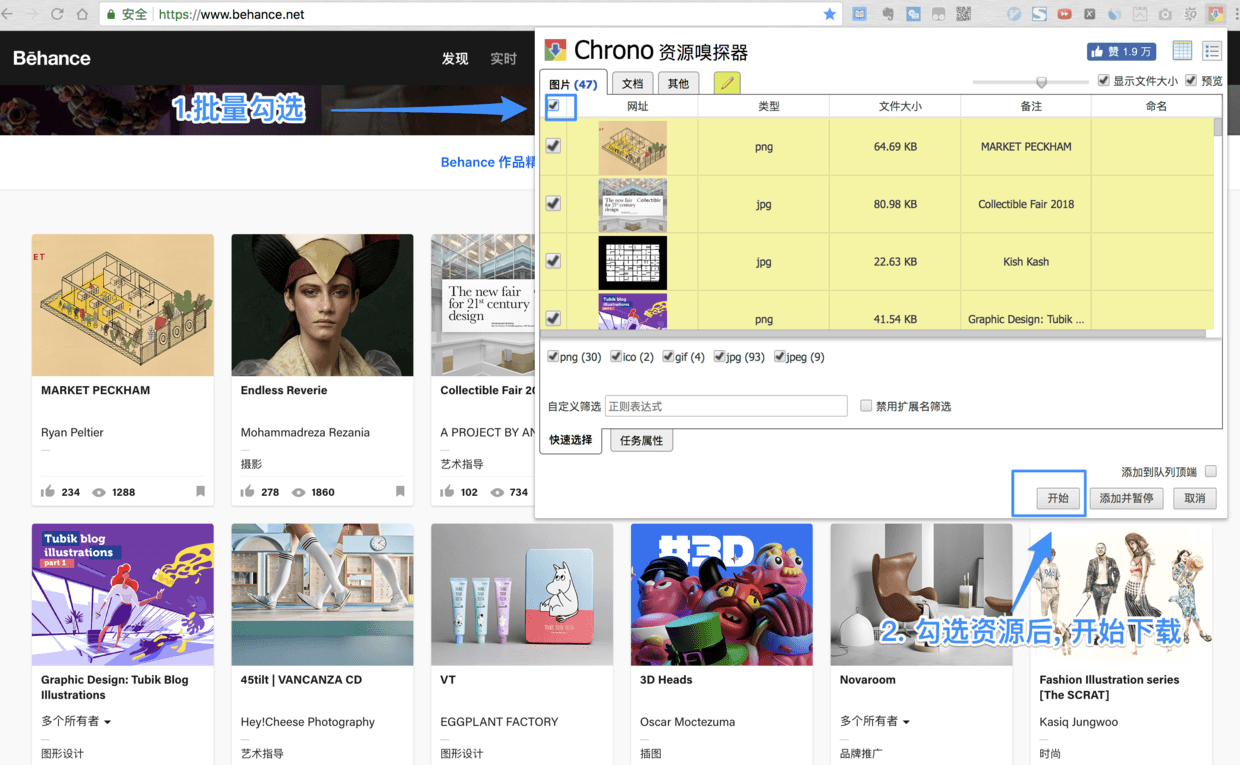
chrono可以对浏览器可见的页面进行资源嗅探, 并批量下载静态资源, 相当于爬虫,如果你是一个设计师, 对批量下载图片情有独钟, 又懒得写爬虫程序, 这个”资源嗅探”的功能或许能提升你下载图片的效率
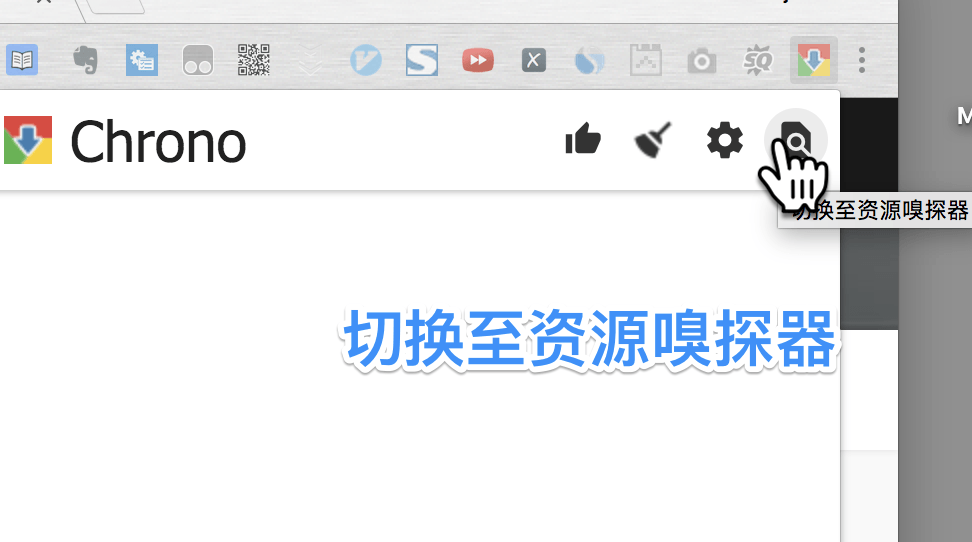
切换至资源嗅探器
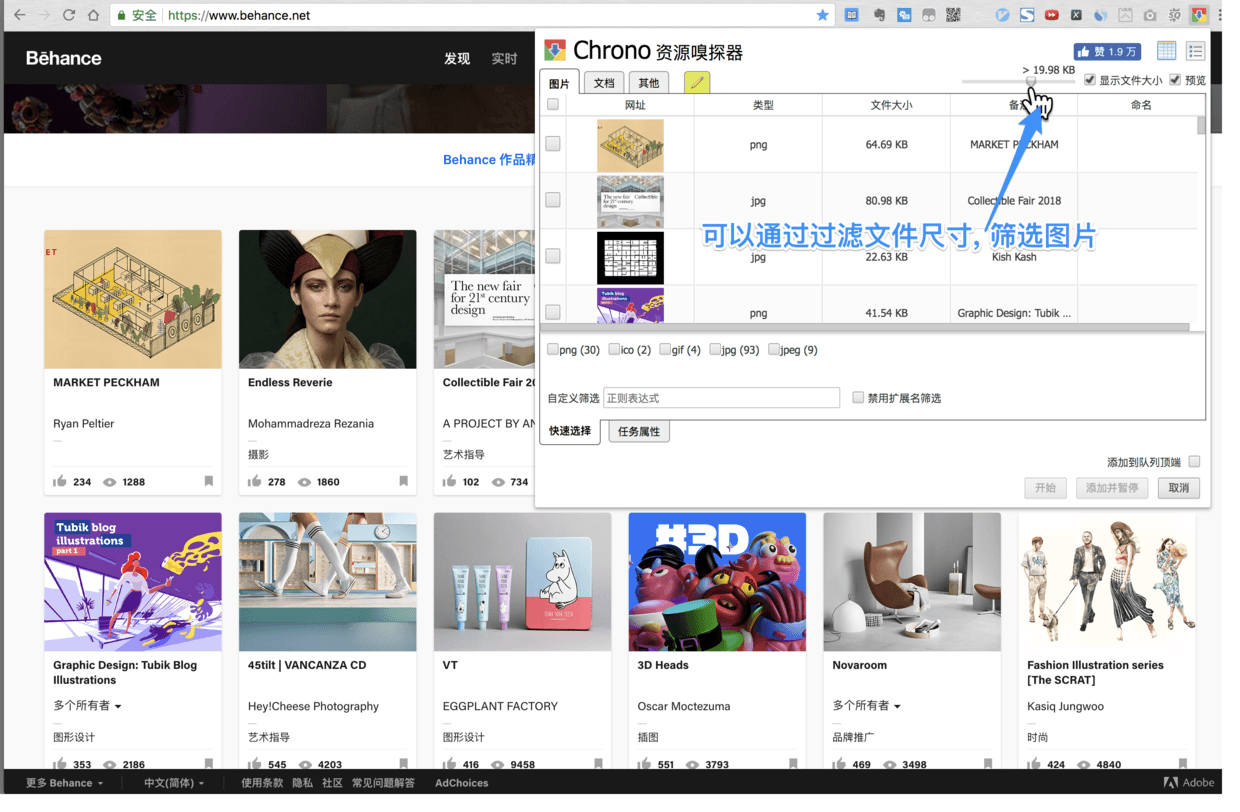
按照图片的空间尺寸, 过滤图片
- 如果你的页面为懒加载(网页根据用户鼠标的滚动, 动态加载图片), 嗅探器会根据页面加载图片数量的变化, 自动添加新图片到嗅探列表
- 过滤文件的尺寸可以设置的稍微大一些(比如200kb以上), 这样可以筛选出, 质量较高的图片
- 批量勾选需要下载的图片, 开始下载
可以批量勾选图片, 也可单独勾选图片, 如果你懂正则, 还可以添加正则表达式来过滤图片(正则一般是留给程序员玩的…)
- 批量下载成功的图片
建议适当提高过滤图片尺寸的标准, 获得尺寸更大, 质量更高的图片(以上展示的图片筛选条件为大于200kb)
本文属于Chrome插件英雄榜 项目的一部分, 项目Github地址: https://github.com/zhaoolee/ChromeAppHeroes
Chrome插件英雄榜, 为优秀的Chrome插件写一本中文说明书, 让Chrome插件英雄们造福人类, 如果你喜欢这个项目, 希望你能为本项目添加一颗 ?星.
ChromeAppHeroes, Write a Chinese manual for the excellent Chrome plugin, let the Chrome plugin heroes benefit the human, If you like this project, I hope you can add a star ? to this project.
现在都知道,现在Chrome浏览器的应用商店都打不开,进不去了,需要翻出去才能上。所以对于一些已经安装过的扩展程序(插件)想导出保存一下。因为Chrome默认安装在C盘,怕重装系统后又要重新安装这些插件了。Chrome其实也自带了这种功能。
打开扩展程序页
打开Chrome菜单中的“更多工具”项中的“扩展程序”。当然,你也可以打开“设置”项,然后再打开扩展程序页。我们就可以看到有“打包扩展程序”这个选项。
找到扩展程序目录
Chrome安装的扩展程序其实都保存在本地磁盘了。Win7系统下Chrome扩展程序的默认保存目录在:C:\Users\Administrator\AppData\Local\Google\Chrome\User Data\Default\Extensions (其中Administrator为当前系统用户,我的就是Administrator)。找到目录后,可以看到目录下有好些都是n多字母为文件名的文件。
查看需要打包的扩展程序的ID
在Chrome的扩展程序页中,可以看到每个安装的扩展的ID(都是唯一的)和版本。版本是很有必要的。
找到扩展程序对应的文件夹
知道ID和版本号后,再到Extensions目录下查找该ID对应的文件夹。
打开文件夹后,找到对应的版本号。也可以看一下文件夹中的文件。
打包扩展程序
1.打开扩展程序页中的“打包扩展程序”按钮
2.选择要打包的扩展程序的根目录
该扩展程序的根目录就是刚才找到的Chrome的Extensions目录下的该扩展ID目录下的,以版本号为名的文件夹。
3.生成打包好的crx文件
选择好目录后,最后点击“打包扩展程序”。打包完成后会提示你打包好的文件位置,其实就是在ID为名的文件夹下。
安装离线插件
Chrome从67.0版本就已经无法离线添加插件了,只能从Chrome应用商店安装(为了提高安全性),对于中国网友那影响可大了,国外网友无所谓,中国网友Chrome应用商店根本打不开,不过在很短时间内(几天)修改hosts文件能达到效果(只能缓解一时),但笔者最近发现之前离线安装的插件在新版本可以使用,所以我们可以先退到67版本以前离线安装,再更新,但太麻烦了。下面有一个很简单的方法,希望能帮助到大家!
打开开发者选项后
出现加载已解压的扩展程序选项
将离线插件的后缀改为压缩包文件,然后解压缩出来,就得到一个文件夹
点击加载已解压的扩展程序
选择解压后的文件夹
成功
最后关闭开发者模式,以免造成Chrome不稳定
(关闭仍能使用)
wordpress 外链跳转 显示403禁止访问
在wordpress中采用外链转内链是加大站点seo权重的一个方法,
利用搜索引擎在网上找到了一组跳转外链的代码:
第一步、新建go文件夹和index.php
在桌面上新建一个go文件夹,然后在里面加一个index.php,在里面粘贴如下代码
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
<?php //$t_url=$_GET['url']; //此代码无法支持带请求参数的目的地址,已弃用! $t_url = preg_replace('/^url=(.*)$/i','$1',$_SERVER["QUERY_STRING"]); //这个支持 if(!empty($t_url)) { preg_match('/(http|https):\/\//',$t_url,$matches); if($matches){ $url=$t_url; $title='页面加载中,请稍候...'; } else { preg_match('/\./i',$t_url,$matche); if($matche){ $url='http://'.$t_url; $title='页面加载中,请稍候...'; } else { $url='http://你的域名/'; $title='参数错误,正在返回首页...'; } } } else { $title='参数缺失,正在返回首页...'; $url='http://你的域名/'; } ?> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8"> <meta http-equiv="refresh" content="1;url='<?php echo $url;?>';"> <title><?php echo $title;?></title> <style> body{background:#000}.loading{-webkit-animation:fadein 2s;-moz-animation:fadein 2s;-o-animation:fadein 2s;animation:fadein 2s}@-moz-keyframes fadein{from{opacity:0}to{opacity:1}}@-webkit-keyframes fadein{from{opacity:0}to{opacity:1}}@-o-keyframes fadein{from{opacity:0}to{opacity:1}}@keyframes fadein{from{opacity:0}to{opacity:1}}.spinner-wrapper{position:absolute;top:0;left:0;z-index:300;height:100%;min-width:100%;min-height:100%;background:rgba(255,255,255,0.93)}.spinner-text{position:absolute;top:50%;left:50%;margin-left:-90px;margin-top: 2px;color:#BBB;letter-spacing:1px;font-weight:700;font-size:36px;font-family:Arial}.spinner{position:absolute;top:50%;left:50%;display:block;margin-left:-160px;width:1px;height:1px;border:25px solid rgba(100,100,100,0.2);-webkit-border-radius:50px;-moz-border-radius:50px;border-radius:50px;border-left-color:transparent;border-right-color:transparent;-webkit-animation:spin 1.5s infinite;-moz-animation:spin 1.5s infinite;animation:spin 1.5s infinite}@-webkit-keyframes spin{0%,100%{-webkit-transform:rotate(0deg) scale(1)}50%{-webkit-transform:rotate(720deg) scale(0.6)}}@-moz-keyframes spin{0%,100%{-moz-transform:rotate(0deg) scale(1)}50%{-moz-transform:rotate(720deg) scale(0.6)}}@-o-keyframes spin{0%,100%{-o-transform:rotate(0deg) scale(1)}50%{-o-transform:rotate(720deg) scale(0.6)}}@keyframes spin{0%,100%{transform:rotate(0deg) scale(1)}50%{transform:rotate(720deg) scale(0.6)}} </style> </head> <body> <div class="loading"> <div class="spinner-wrapper"> <span class="spinner-text">页面加载中,请稍候...</span> <span class="spinner"></span> </div> </div> </body> </html> |
脚下留心:这个代码中加了些css效果用于美化,如果你不需要这个装逼特效,可以换成这个代码
|
1 2 3 4 |
<?php $url = $_GET['url']; Header("Location:$url"); ?> |
然后把go整个文件夹通过ftp工具传到网站根目录(跟wp-admin,wp-content平行的目录)
打开主题文件夹下的functions.php,加入以下代码
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
//给外部链接加上跳转 add_filter('the_content','the_content_nofollow',999); function the_content_nofollow($content) { preg_match_all('/<a(.*?)href="(.*?)"(.*?)>/',$content,$matches); if($matches){ foreach($matches[2] as $val){ if(strpos($val,'://')!==false && strpos($val,home_url())===false && !preg_match('/\.(jpg|jepg|png|ico|bmp|gif|tiff)/i',$val)){ $content=str_replace("href=\"$val\"", "href=\"".home_url()."/go/?url=$val\" target='_blank'",$content); } } } return $content; } |
打开百度站长平台,进入左边的Robots,在里面加入这句
Disallow: /go/